Overview
The Dynamo AI system runs in your Kubernetes cluster on-premises or on-cloud. This deployment guide covers deploying the Dynamo AI system in AWS and on-prem environments. Detailed deployment guide for Azure, GCP and other environments will be published soon. If you have questions, please feel free to reach out to Dynamo AI.
Architecture overview
The following graph illustrates the architecture of an example system setup on-premises, including the integrated systems running in your Corporation VPN and production environment.

The Dynamo AI system is deployed in a dedicated namespace in Kubernetes. The Kubernetes cluster is managed by you in your production environment.
Components
- Web Server and API Server: The applications that serve the UI and the APIs to the Dynamo AI system.
- Keycloak: A Keycloak based application that serves the authentication and authorization for all incoming requests.
- Redis: A Redis based application that queues the asynchronous jobs.
- ML workers: Depending on your setup, there are various ML workers that generate the test prompts, generate policies, moderate realtime traffic, etc. The ML servers can be automatically scaled up and down.
- PostgreSQL and MongoDB: Dynamo AI can run PostgreSQL and MongoDB instances in the system. They are used for storing the system configuration and application data. Alternatively, Dynamo AI can integrate with the PostgreSQL and MongoDB services managed by your infrastructure.
- FluentBit: A FluentBit application that collects the application logs from the system.
System personas
Generally, there are four groups of personas who may interact with the Dynamo AI system for usage and maintenance purposes:
- General Users: External and internal users who utilize the LLM inference service. Users could interact with 1st party LLM UI that is hosted by LLM Web Server running in your corporation, Your Web Server calls Dynamo AI service to guardrail the traffic. Alternatively, users could interact with 3rd party LLM UI such as Microsoft Co-pilot or ChatGPT. In this case, the web browser extension installed on the web browser intercepts the traffic, and calls Dynamo AI service to guardrail the traffic.
- System Admin: Administrators responsible for managing system configurations and setting user permissions. They manages the system through the Dynamo UI admin dashboard.
- ML Engineers: ML Engineers who run the tests, develop and apply the policies. ML engineers can use the Dynamo UI or Dynamo SDK to interact with the system.
- DevOps: Engineers who deploy and manage the system, and monitor the system metrics. They regularlly update the system to upgrade the features and fix vulnerabilities.
Interaction with external systems and alternatives
The Dynamo AI system may interact with other systems in the following ways:
-
Web service and API service: Dynamo AI exposes the Web Server and API Server services to serve the incoming traffic from web browsers or SDK.
-
Integration with IAM Systems: If you have an existing IAM system, Dynamo AI can integrate with it using Keycloak, which connects via the OIDC endpoint.
-
Keycloak Admin Dashboard: To access advanced authentication and authorization features, such as SSO configuration, you may need to access the Keycloak Admin Dashboard.
-
Model and Configuration Storage and Retrieval:
- If your organization has an existing Object Storage service, ML workers can download/upload Dynamo AI models from/to your organization's Object Storage service.
- If your cluster has access to Hugging Face, ML workers can retrieve Dynamo AI models from this external service.
- Otherwise, Dynamo AI can deploy an in-cluster MinIO service for object storage. Models can also be shipped to you directly from Dynamo AI.
-
External LLM Services:
- ML workers can call external LLM service endpoints, such as Mistral AI, to generate synthetic prompts and datasets.
- Alternatively, you can host open-source models locally, which requires additional GPUs.
-
Managed Inference with DynamoGuard: When using DynamoGuard in managed inference mode, and if the target LLM is external, ML workers send compliant prompts to the external LLM service endpoints to receive inference responses.
-
Log Management:
DynamoGuard service modes
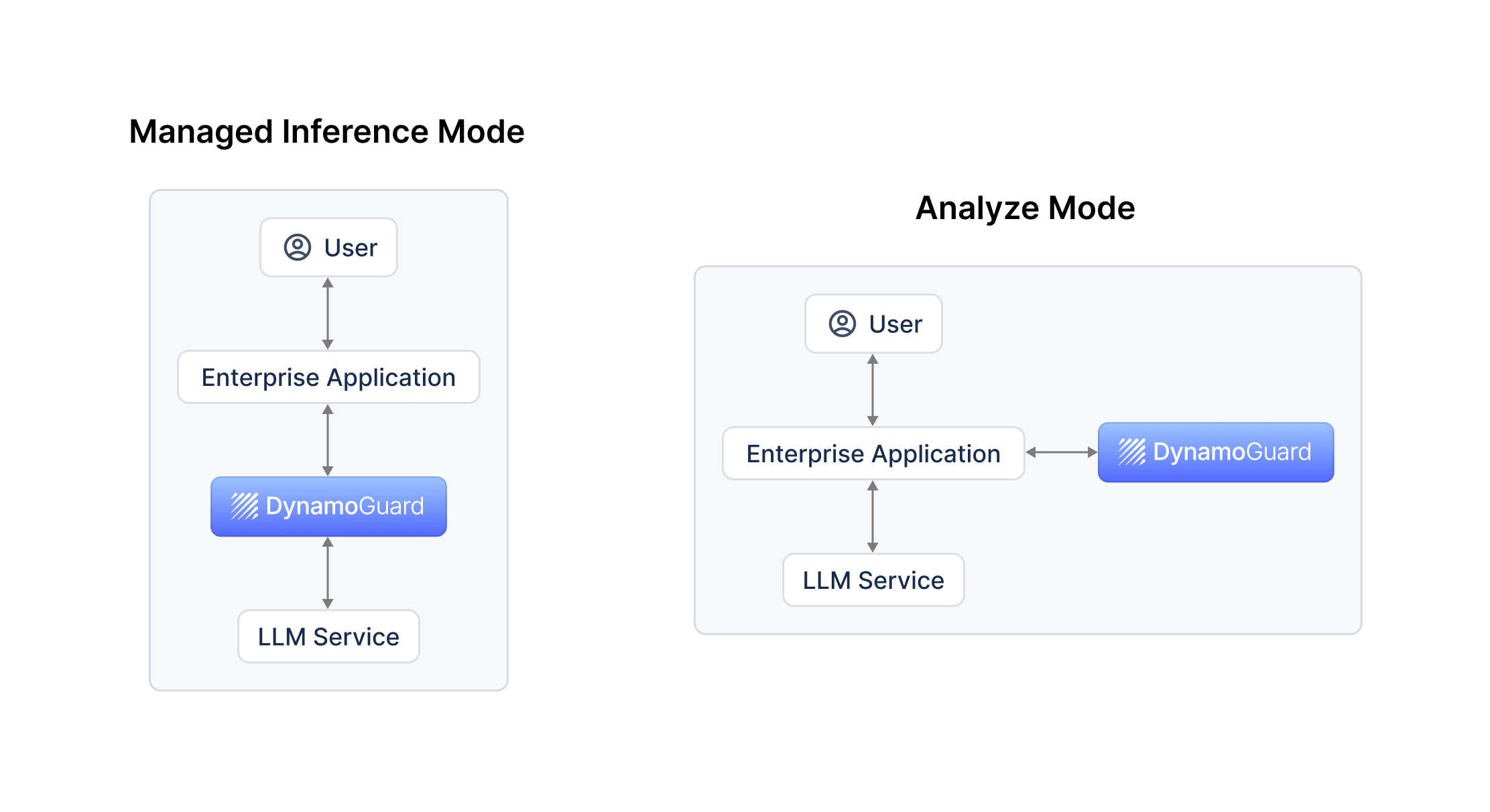
The DynamoGuard can run in two different service modes, managed inference mode and analyze mode. The following graph shows the two modes on the high level.
-
Managed inference mode: DynamoGuard serves as a proxy to the target LLM service. It moderates the input prompt, forwards compliant requests to the target LLM service, receives the inference result, and moderates the response before sending it to the user. Your application sends the LLM prompt to DynamoGuard and receives the inference response (or an error message if the request is non-compliant) from DynamoGuard.
-
Analyze mode: DynamoGuard moderates the input and output to and from the target LLM service without forwarding the request itself. Your application directly calls the LLM service for inference and calls DynamoGuard separately to moderate the input and output. If you are using the browser extension to intercept traffic, you are using Analyze Mode.